
@ Generative AI exists because of the transformer
++ FT Java Off
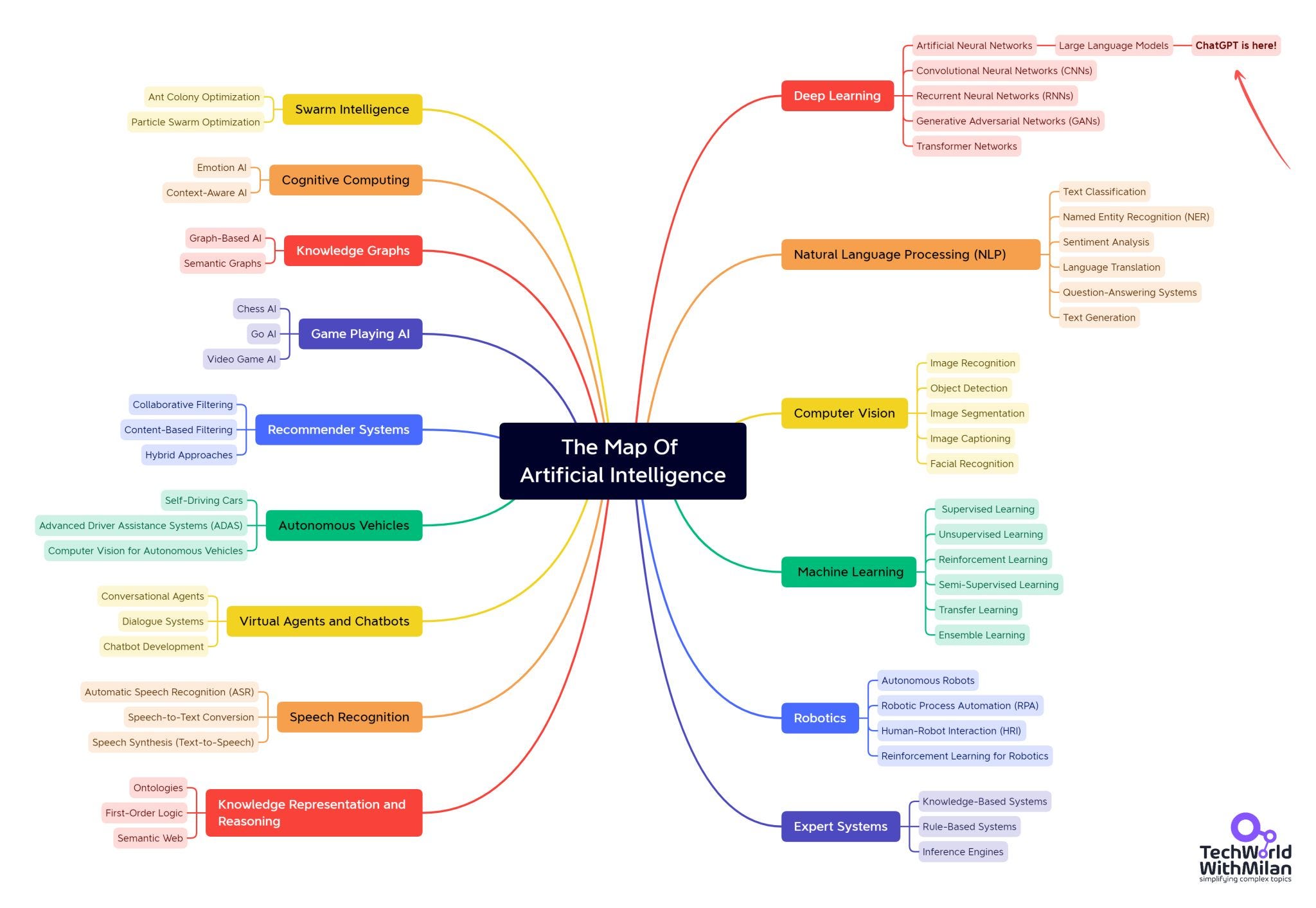
INCLUDES: The architecture of Transformers: self-attention, encoder–decoder design, positional encoding, and multi-head attention KEY CONCEPTS: Attention mechanism, embeddings, residual connections, normalization, feed-forward layers, and decoder workflows, Tokenization, Tokens
11-13 Data Sets Like Common Crawl. https://docs.google.com/document/d/1BWLfTqTq79FXO72Yj459SthgzvoP-n5cghZwjkrWHW0/edit?tab=t.0
+++NEW - Book Example 11/1
10-30, 11-13 LEE & TROT Hidden State https://docs.google.com/document/d/1-ra-X_eziXjy4oR5-MUR4lNLwG3wm55RvW4U6mE0cG0/edit?usp=sharing
10-20, ...,11-8 Deep learning inspired by human brain. Uses neural networks. Layers - hidden middle.
Machine vs Deep Learning https://docs.google.com/document/d/1GQbJoqiIj0CGJXxiqnb4duj835q28HPs2QlFUu9hyyQ/edit?tab=t.0
11-13 Graphic: https://substackcdn.com/image/fetch/$s_!bbIF!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F913c0977-d2f6-4d8e-aae6-39f9e35c14cd_2048x1413.jpeg Transformers, E&D, Attention, UNFINISHED













{kind=link}