Improved Baselines with Visual Instruction Tuning

Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
null
LIMA: Less Is More for Alignment
IMAGEBIND: One Embedding Space To Bind Them All
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Language models are increasingly being deployed for general problem solving
across a wide range of tasks, but are still confined to token-level,
left-to-right decision-making processes during inference. This means they can
fall short in tasks that require exploration, strategic lookahead, or where
initial decisions play a pivotal role. To surmount these challenges, we
introduce a new framework for language model inference, Tree of Thoughts (ToT),
which generalizes over the popular Chain of Thought approach to prompting
language models, and enables exploration over coherent units of text (thoughts)
that serve as intermediate steps toward problem solving. ToT allows LMs to
perform deliberate decision making by considering multiple different reasoning
paths and self-evaluating choices to decide the next course of action, as well
as looking ahead or backtracking when necessary to make global choices. Our
experiments show that ToT significantly enhances language models'
problem-solving abilities on three novel tasks requiring non-trivial planning
or search: Game of 24, Creative Writing, and Mini Crosswords. For instance, in
Game of 24, while GPT-4 with chain-of-thought prompting only solved 4% of
tasks, our method achieved a success rate of 74%. Code repo with all prompts:
https://github.com/ysymyth/tree-of-thought-llm.
MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers
TRAIN SHORT, TEST LONG: ATTENTION WITH LINEAR BIASES ENABLES INPUT LENGTH EXTRAPOLATION

Quantization - Qdrant
Qdrant is an Open-Source Vector Database and Vector Search Engine written in Rust. It provides fast and scalable vector similarity search service with convenient API.
Quantization is an optional feature in Qdrant that enables efficient storage and search of high-dimensional vectors.
By transforming original vectors into a new representations, quantization compresses data while preserving close to original relative distances between vectors.
Different quantization methods have different mechanics and tradeoffs. We will cover them in this section.

Backpropagation through time - Wikipedia
Backpropagation through time (BPTT) is a gradient-based technique for training certain types of recurrent neural networks. It can be used to train Elman networks. The algorithm was independently derived by numerous researchers
Emergent and Predictable Memorization in Large Language Models
Memorization, or the tendency of large language models (LLMs) to output
entire sequences from their training data verbatim, is a key concern for safely
deploying language models. In particular, it is vital to minimize a model's
memorization of sensitive datapoints such as those containing personal
identifiable information (PII). The prevalence of such undesirable memorization
can pose issues for model trainers, and may even require discarding an
otherwise functional model. We therefore seek to predict which sequences will
be memorized before a large model's full train-time by extrapolating the
memorization behavior of lower-compute trial runs. We measure memorization of
the Pythia model suite, and find that intermediate checkpoints are better
predictors of a model's memorization behavior than smaller fully-trained
models. We additionally provide further novel discoveries on the distribution
of memorization scores across models and data.
The paper "Emergent and Predictable Memorization in Large Language Models" by Stella Biderman et al. studies the problem of memorization in large language models and proposes a method to predict which sequences will be memorized before full training of the model, based on extrapolation of memorization behavior from lower-compute trial runs, and provides novel insights on the distribution of memorization scores across models and data.
Key insights and lessons learned from the paper:
Memorization is a key concern for deploying large language models safely, particularly for sensitive datapoints such as PII.
Intermediate checkpoints are better predictors of memorization behavior than smaller fully-trained models.
Memorization scores follow a power-law distribution across models and data, with some datapoints being more prone to memorization than others.
Fine-tuning can mitigate memorization to some extent, but not completely.
The Forward-Forward Algorithm: Some Preliminary Investigations

Evidence of a predictive coding hierarchy in the human brain listening to speech - Nature Human Behaviour
Current machine learning language algorithms make adjacent word-level predictions. In this work, Caucheteux et al. show that the human brain probably uses long-range and hierarchical predictions, taking into account up to eight possible words into the future.
Recurrent Memory Transformer
Transformer-based models show their effectiveness across multiple domains and
tasks. The self-attention allows to combine information from all sequence
elements into context-aware representations. However, global and local
information has to be stored mostly in the same element-wise representations.
Moreover, the length of an input sequence is limited by quadratic computational
complexity of self-attention.
In this work, we propose and study a memory-augmented segment-level recurrent
Transformer (RMT). Memory allows to store and process local and global
information as well as to pass information between segments of the long
sequence with the help of recurrence.
We implement a memory mechanism with no changes to Transformer model by
adding special memory tokens to the input or output sequence. Then the model is
trained to control both memory operations and sequence representations
processing.
Results of experiments show that RMT performs on par with the Transformer-XL
on language modeling for smaller memory sizes and outperforms it for tasks that
require longer sequence processing. We show that adding memory tokens to Tr-XL
is able to improve its performance. This makes Recurrent Memory Transformer a
promising architecture for applications that require learning of long-term
dependencies and general purpose in memory processing, such as algorithmic
tasks and reasoning.
The paper "Recurrent Memory Transformer" proposes a memory-augmented segment-level recurrent Transformer (RMT) model that stores and processes global and local information by adding memory tokens to the input or output sequence, and shows that RMT performs on par with Transformer-XL on language modeling for smaller memory sizes and outperforms it for longer sequence processing tasks.
Key insights and lessons learned:
The self-attention mechanism in Transformer-based models has quadratic computational complexity for long sequences and limits the amount of global and local information that can be stored and processed.
Adding memory tokens to the input or output sequence of a Transformer-based model allows for memory-augmentation and the storage and processing of global and local information, as well as the passing of information between segments of long sequences with the help of recurrence.
The proposed RMT model performs on par with Transformer-XL on language modeling for smaller memory sizes and outperforms it for longer sequence processing tasks.
The RMT model can be applied to a wide range of tasks and domains, including natural language processing and image recognition.
Stochastic variance reduction - Wikipedia
(Stochastic) variance reduction is an algorithmic approach to minimizing functions that can be decomposed into finite sums. By exploiting the finite sum structure, variance reduction techniques are able to achieve convergence rates that are impossible to achieve with methods that treat the objective as an infinite sum, as in the classical Stochastic approximation setting.
Variance reduction approaches are widely used for training machine learning models such as logistic regression and support vector machines[1] as these problems have finite-sum structure and uniform conditioning that make them ideal candidates for variance reduction.
Stochastic approximation - Wikipedia
Stochastic approximation methods are a family of iterative methods typically used for root-finding problems or for optimization problems. The recursive update rules of stochastic approximation methods can be used, among other things, for solving linear systems when the collected data is corrupted by noise, or for approximating extreme values of functions which cannot be computed directly, but only estimated via noisy observations.

Stochastic gradient descent - Wikipedia
Stochastic gradient descent (often abbreviated SGD) is an iterative method for optimizing an objective function with suitable smoothness properties (e.g. differentiable or subdifferentiable). It can be regarded as a stochastic approximation of gradient descent optimization, since it replaces the actual gradient (calculated from the entire data set) by an estimate thereof (calculated from a randomly selected subset of the data). Especially in high-dimensional optimization problems this reduces the very high computational burden, achieving faster iterations in trade for a lower convergence rate
Bigram - Wikipedia
A bigram or digram is a sequence of two adjacent elements from a string of tokens, which are typically letters, syllables, or words. A bigram is an n-gram for n=2. The frequency distribution of every bigram in a string is commonly used for simple statistical analysis of text in many applications, including in computational linguistics, cryptography, speech recognition, and so on.
Gappy bigrams or skipping bigrams are word pairs which allow gaps (perhaps avoiding connecting words, or allowing some simulation of dependencies, as in a dependency grammar).
Head word bigrams are gappy bigrams with an explicit dependency relationship.

Natural Language Inference: An Overview
Benchmark and models
Natural Language Inference (NLI) is the task of determining whether the given “hypothesis” logically follows from the “premise”. In layman’s terms, you need to understand whether the hypothesis is true, while the premise is your only knowledge about the subject.
Natural-language understanding - Wikipedia
Natural-language understanding (NLU) or natural-language interpretation (NLI)[1] is a subtopic of natural-language processing in artificial intelligence that deals with machine reading comprehension. Natural-language understanding is considered an AI-hard problem.[2]
There is considerable commercial interest in the field because of its application to automated reasoning,[3] machine translation,[4] question answering,[5] news-gathering, text categorization, voice-activation, archiving, and large-scale content analysis.

AI alignment - Wikipedia
In the field of artificial intelligence (AI), AI alignment research aims to steer AI systems towards their designers’ intended goals and interests.[a] An AI system is described as misaligned if it is competent but advances an unintended objective
Tokenization
Given a character sequence and a defined document unit, tokenization is
the task of chopping it up
into pieces, called tokens , perhaps
at the same time
throwing away certain characters, such as punctuation

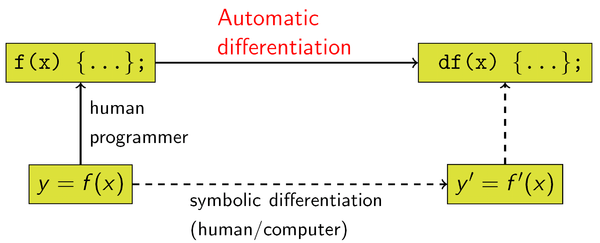
Automatic differentiation - Wikipedia
Automatic differentiation is distinct from symbolic differentiation and numerical differentiation.
Symbolic differentiation faces the difficulty of converting a computer program into a single mathematical expression and can lead to inefficient code. Numerical differentiation (the method of finite differences) can introduce round-off errors in the discretization process and cancellation. Both of these classical methods have problems with calculating higher derivatives, where complexity and errors increase. Finally, both of these classical methods are slow at computing partial derivatives of a function with respect to many inputs, as is needed for gradient-based optimization algorithms. Automatic differentiation solves all of these problems.
NeuralNet from scratch

automatic differentiation nutshell
{kind=link}

Effect of Regularization in Neural Net Training
co-authored with Daryl Chang
On applying dropout, the distribution of weights across all layers changes from a zero mean uniform distribution to a zero mean gaussian distribution. This is similar to the weight decaying effect of L2 regularization on model weights
Linear separability: Sparse representations are also more likely to be linearly separable, or more easily separable with less non-linear machinery, simply because the information is represented in a high-dimensional space.
Moravec's paradox - Wikipedia
Moravec's paradox is the observation by artificial intelligence and robotics researchers that, contrary to traditional assumptions, reasoning requires very little computation, but sensorimotor and perception skills require enormous computational resources. The principle was articulated by Hans Moravec, Rodney Brooks, Marvin Minsky and others in the 1980s. Moravec wrote in 1988, "it is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility".[1]
Moravec's paradox is the observation by artificial intelligence and robotics researchers that, contrary to traditional assumptions, reasoning requires very little computation, but sensorimotor and perception skills require enormous computational resources. The principle was articulated by Hans Moravec, Rodney Brooks, Marvin Minsky and others in the 1980s. Moravec wrote in 1988, "it is comparatively easy to make computers exhibit adult level performance on intelligence tests or playing checkers, and difficult or impossible to give them the skills of a one-year-old when it comes to perception and mobility"

Joint Embedding Methods - Contrastive · Deep Learning
Joint Embedding methods try to make their backbone network robust to certain distortions and are invariant to data augmentation.
Cerebras-GPT: Open Compute-Optimal Language Models Trained on the Cerebras Wafer-Scale Cluster
PANGU-Σ: TOWARDS TRILLION PARAMETER LANGUAGE MODEL WITH SPARSE HETEROGENEOUS COMPUTING
REAC T: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS