Robust Preference Learning for Storytelling via Contrastive Reinforcement Learning
MAGMA -- Multimodal Augmentation of Generative Models through Adapter-based Finetuning
Large-scale pretraining is fast becoming the norm in Vision-Language (VL)
modeling. However, prevailing VL approaches are limited by the requirement for
labeled data and the use of complex multi-step pretraining objectives. We
present MAGMA - a simple method for augmenting generative language models with
additional modalities using adapter-based finetuning. Building on Frozen, we
train a series of VL models that autoregressively generate text from arbitrary
combinations of visual and textual input. The pretraining is entirely
end-to-end using a single language modeling objective, simplifying optimization
compared to previous approaches. Importantly, the language model weights remain
unchanged during training, allowing for transfer of encyclopedic knowledge and
in-context learning abilities from language pretraining. MAGMA outperforms
Frozen on open-ended generative tasks, achieving state of the art results on
the OKVQA benchmark and competitive results on a range of other popular VL
benchmarks, while pretraining on 0.2% of the number of samples used to train
SimVLM.
MAGMA - a simple method for augmenting generative language models with
additional modalities using adapter-based finetuning. Building on Frozen, we
train a series of VL models that autoregressively generate text from arbitrary
combinations of visual and textual input. The pretraining is entirely
end-to-end using a single language modeling objective, simplifying optimization
compared to previous approaches. Importantly, the language model weights remain
unchanged during training, allowing for transfer of encyclopedic knowledge and
in-context learning abilities from language pretraining. MAGMA outperforms
Frozen on open-ended generative tasks, achieving state of the art results on
the OKVQA benchmark and competitive results on a range of other popular VL
benchmarks, while pretraining on 0.2% of the number of samples used to train
SimVLM.
Protein structure generation via folding diffusion

DreamFusion: Text-to-3D using 2D Diffusion
DreamFusion: Text-to-3D using 2D Diffusion, 2022.
Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D assets and efficient architectures for denoising 3D data, neither of which currently exist. In this work, we circumvent these limitations by using a pretrained 2D text-to-image diffusion model to perform text-to-3D synthesis. We introduce a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator. Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
Dreamfusion

Zero-Shot Video Question Answering via Frozen Bidirectional Language Models
In particular, (i) we combine visual inputs with the frozen BiLM using light trainable modules,
(ii) we train such modules using Web-scraped multi-modal data, and finally
(iii) we perform zero-shot VideoQA inference through masked language modeling, where the masked text is the answer to a given question.
Our proposed approach, FrozenBiLM, outperforms the state of the art in zero-shot VideoQA by a significant margin on a variety of datasets, including LSMDC-FiB, iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, TGIF-FrameQA, How2QA and TVQA.
It also demonstrates competitive performance in the few-shot and fully-supervised setting.
Our code and models will be made publicly available.
Highly accurate protein structure prediction with AlphaFold

AlphaFold reveals the structure of the protein universe
Today, in partnership with EMBL’s European Bioinformatics Institute (EMBL-EBI), we’re now releasing predicted structures for nearly all catalogued proteins known to science, which will expand the AlphaFold DB by over 200x - from nearly 1 million structures to over 200 million structures - with the potential to dramatically increase our understanding of biology.
In partnership with EMBL’s European Bioinformatics Institute (EMBL-EBI), we’re now releasing predicted structures for nearly all catalogued proteins known to science, which will expand the AlphaFold DB by over 200x - from nearly 1 million structures to over 200 million structures - with the potential to dramatically increase our understanding of biology.
.svg?width=350&height=&ar=16:9&mode=crop&format=avif&dpr=2)
Number of protein structure
.svg){kind=link}
Fine-Tuning Language Models from Human Preferences

Energy-based model

Potentials & challenge cross-silo federated learning
Cross-Silo Federated Learning: Challenges and Opportunities
Federated learning (FL) is an emerging technology that enables the training
of machine learning models from multiple clients while keeping the data
distributed and private. Based on the participating clients and the model
training scale, federated learning can be classified into two types:
cross-device FL where clients are typically mobile devices and the client
number can reach up to a scale of millions; cross-silo FL where clients are
organizations or companies and the client number is usually small (e.g., within
a hundred). While existing studies mainly focus on cross-device FL, this paper
aims to provide an overview of the cross-silo FL. More specifically, we first
discuss applications of cross-silo FL and outline its major challenges. We then
provide a systematic overview of the existing approaches to the challenges in
cross-silo FL by focusing on their connections and differences to cross-device
FL. Finally, we discuss future directions and open issues that merit research
efforts from the community.
federated learning can be classified into two types:
cross-device FL where clients are typically mobile devices and the client
number can reach up to a scale of millions; cross-silo FL where clients are
organizations or companies and the client number is usually small (e.g., within
a hundred)
Cross-Silo Federated Learning: Challenges and Opportunities
SplitFed: When Federated Learning Meets Split Learning
THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption
As more and more pre-trained language models adopt on-cloud deployment, the
privacy issues grow quickly, mainly for the exposure of plain-text user data
(e.g., search history, medical record, bank account). Privacy-preserving
inference of transformer models is on the demand of cloud service users. To
protect privacy, it is an attractive choice to compute only with ciphertext in
homomorphic encryption (HE). However, enabling pre-trained models inference on
ciphertext data is difficult due to the complex computations in transformer
blocks, which are not supported by current HE tools yet. In this work, we
introduce $\textit{THE-X}$, an approximation approach for transformers, which
enables privacy-preserving inference of pre-trained models developed by popular
frameworks. $\textit{THE-X}$ proposes a workflow to deal with complex
computation in transformer networks, including all the non-polynomial functions
like GELU, softmax, and LayerNorm. Experiments reveal our proposed
$\textit{THE-X}$ can enable transformer inference on encrypted data for
different downstream tasks, all with negligible performance drop but enjoying
the theory-guaranteed privacy-preserving advantage.
THE-X proposes a workflow to deal with complex computation in transformer networks, including all the non-polynomial functions like GELU, softmax, and LayerNorm. Experiments reveal our proposed THE-X can enable transformer inference on encrypted data for different downstream tasks, all with negligible performance drop but enjoying the theory-guaranteed privacy-preserving advantage.
Denoising Diffusion Probabilistic Models
We present high quality image synthesis results using diffusion probabilistic
models, a class of latent variable models inspired by considerations from
nonequilibrium thermodynamics. Our best results are obtained by training on a
weighted variational bound designed according to a novel connection between
diffusion probabilistic models and denoising score matching with Langevin
dynamics, and our models naturally admit a progressive lossy decompression
scheme that can be interpreted as a generalization of autoregressive decoding.
On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and
a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality
similar to ProgressiveGAN. Our implementation is available at
https://github.com/hojonathanho/diffusion
We present high quality image synthesis results using diffusion probabilistic
models, a class of latent variable models inspired by considerations from
nonequilibrium thermodynamics. Our best results are obtained by training on a
weighted variational bound designed according to a novel connection between
diffusion probabilistic models and denoising score matching with Langevin
dynamics, and our models naturally admit a progressive lossy decompression
scheme that can be interpreted as a generalization of autoregressive decoding
ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech
Denoising diffusion probabilistic models (DDPMs) have recently achieved
leading performances in many generative tasks. However, the inherited iterative
sampling process costs hinder their applications to text-to-speech deployment.
Through the preliminary study on diffusion model parameterization, we find that
previous gradient-based TTS models require hundreds or thousands of iterations
to guarantee high sample quality, which poses a challenge for accelerating
sampling. In this work, we propose ProDiff, on progressive fast diffusion model
for high-quality text-to-speech. Unlike previous work estimating the gradient
for data density, ProDiff parameterizes the denoising model by directly
predicting clean data to avoid distinct quality degradation in accelerating
sampling. To tackle the model convergence challenge with decreased diffusion
iterations, ProDiff reduces the data variance in the target site via knowledge
distillation. Specifically, the denoising model uses the generated
mel-spectrogram from an N-step DDIM teacher as the training target and distills
the behavior into a new model with N/2 steps. As such, it allows the TTS model
to make sharp predictions and further reduces the sampling time by orders of
magnitude. Our evaluation demonstrates that ProDiff needs only 2 iterations to
synthesize high-fidelity mel-spectrograms, while it maintains sample quality
and diversity competitive with state-of-the-art models using hundreds of steps.
ProDiff enables a sampling speed of 24x faster than real-time on a single
NVIDIA 2080Ti GPU, making diffusion models practically applicable to
text-to-speech synthesis deployment for the first time. Our extensive ablation
studies demonstrate that each design in ProDiff is effective, and we further
show that ProDiff can be easily extended to the multi-speaker setting. Audio
samples are available at \url{https://ProDiff.github.io/.}
Denoising diffusion probabilistic models (DDPMs) have recently achieved
leading performances in many generative tasks. However, the inherited iterative
sampling process costs hinder their applications to text-to-speech deployment.
Through the preliminary study on diffusion model parameterization, we find that
previous gradient-based TTS models require hundreds or thousands of iterations
to guarantee high sample quality, which poses a challenge for accelerating
sampling. In this work, we propose ProDiff, on progressive fast diffusion model
for high-quality text-to-speech. Unlike previous work estimating the gradient
for data density, ProDiff parameterizes the denoising model by directly
predicting clean data to avoid distinct quality degradation in accelerating
sampling. To tackle the model convergence challenge with decreased diffusion
iterations, ProDiff reduces the data variance in the target site via knowledge
distillation
A Generalist Neural Algorithmic Learner
The cornerstone of neural algorithmic reasoning is the ability to solve
algorithmic tasks, especially in a way that generalises out of distribution.
While recent years have seen a surge in methodological improvements in this
area, they mostly focused on building specialist models. Specialist models are
capable of learning to neurally execute either only one algorithm or a
collection of algorithms with identical control-flow backbone. Here, instead,
we focus on constructing a generalist neural algorithmic learner -- a single
graph neural network processor capable of learning to execute a wide range of
algorithms, such as sorting, searching, dynamic programming, path-finding and
geometry. We leverage the CLRS benchmark to empirically show that, much like
recent successes in the domain of perception, generalist algorithmic learners
can be built by "incorporating" knowledge. That is, it is possible to
effectively learn algorithms in a multi-task manner, so long as we can learn to
execute them well in a single-task regime. Motivated by this, we present a
series of improvements to the input representation, training regime and
processor architecture over CLRS, improving average single-task performance by
over 20% from prior art. We then conduct a thorough ablation of multi-task
learners leveraging these improvements. Our results demonstrate a generalist
learner that effectively incorporates knowledge captured by specialist models.
The cornerstone of neural algorithmic reasoning is the ability to solve
algorithmic tasks, especially in a way that generalises out of distribution.
While recent years have seen a surge in methodological improvements in this
area, they mostly focused on building specialist models. Specialist models are
capable of learning to neurally execute either only one algorithm or a
collection of algorithms with identical control-flow backbone. Here, instead,
we focus on constructing a generalist neural algorithmic learner -- a single
graph neural network processor capable of learning to execute a wide range of
algorithms, such as sorting, searching, dynamic programming, path-finding and
geometry. We leverage the CLRS benchmark to empirically show that, much like
recent successes in the domain of perception, generalist algorithmic learners
can be built by "incorporating" knowledge. That is, it is possible to
effectively learn algorithms in a multi-task manner, so long as we can learn to
execute them well in a single-task regime. Motivated by this, we present a
series of improvements to the input representation, training regime and
processor architecture over CLRS, improving average single-task performance by
over 20% from prior art. We then conduct a thorough ablation of multi-task
learners leveraging these improvements. Our results demonstrate a generalist
learner that effectively incorporates knowledge captured by specialist models.

LLM in business

Learning to Walk by Steering: Perceptive Quadrupedal Locomotion in Dynamic Environments
We present a hierarchical learning framework, named PRELUDE, which decomposes the problem of perceptive locomotion into high-level decision-making to predict navigation commands and low-level gait generation to realize the target commands. In this framework, we train the high-level navigation controller with imitation learning on human demonstrations collected on a steerable cart and the low-level gait controller with reinforcement learning (RL). Therefore, our method can acquire complex navigation behaviors from human supervision and discover versatile gaits from trial and error

NLMap-SayCan
Project page for Open-vocabulary Queryable Scene Representations for Real World Planning
In this paper, we develop NLMap, an
open-vocabulary and queryable scene representation to address this
problem. NLMap serves as a framework to gather and integrate
contextual information into LLM planners, allowing them to see and
query available objects in the scene before generating a
context-conditioned plan. NLMap first establishes a natural language
queryable scene representation with Visual Language models (VLMs). An
LLM based object proposal module parses instructions and proposes
involved objects to query the scene representation for object
availability and location. An LLM planner then plans with such
information about the scene. NLMap allows robots to operate without a
fixed list of objects nor executable options, enabling real robot
operation unachievable by previous methods.

The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
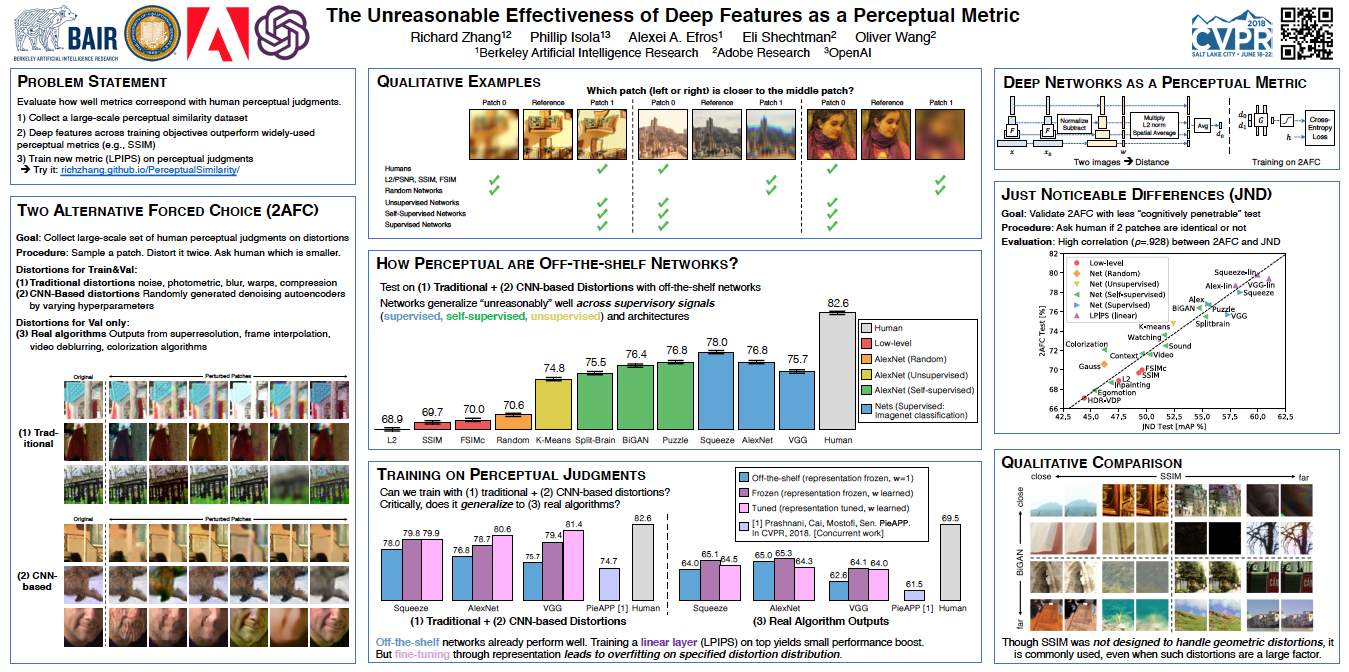{kind=link}
Pure Transformers are Powerful Graph Learners
We show that standard Transformers without graph-specific modifications can
lead to promising results in graph learning both in theory and practice. Given
a graph, we simply treat all nodes and edges as independent tokens, augment
them with token embeddings, and feed them to a Transformer. With an appropriate
choice of token embeddings, we prove that this approach is theoretically at
least as expressive as an invariant graph network (2-IGN) composed of
equivariant linear layers, which is already more expressive than all
message-passing Graph Neural Networks (GNN). When trained on a large-scale
graph dataset (PCQM4Mv2), our method coined Tokenized Graph Transformer
(TokenGT) achieves significantly better results compared to GNN baselines and
competitive results compared to Transformer variants with sophisticated
graph-specific inductive bias. Our implementation is available at
https://github.com/jw9730/tokengt.
We show that standard Transformers without graph-specific modifications can
lead to promising results in graph learning both in theory and practice. Given
a graph, we simply treat all nodes and edges as independent tokens, augment
them with token embeddings, and feed them to a Transformer. With an appropriate
choice of token embeddings, we prove that this approach is theoretically at
least as expressive as an invariant graph network (2-IGN) composed of
equivariant linear layers, which is already more expressive than all
message-passing Graph Neural Networks (GNN). When trained on a large-scale
graph dataset (PCQM4Mv2), our method coined Tokenized Graph Transformer
(TokenGT) achieves significantly better results compared to GNN baselines and
competitive results compared to Transformer variants with sophisticated
graph-specific inductive bias. Our implementation is available at
this https URL.

Test-Time Prompt Tuning for Zero-shot Generalization in Vision-Language Models
Pre-trained vision-language models (e.g., CLIP) have shown impressive zero-shot
generalization in various downstream tasks with properly designed text prompts. Instead of relying on hand-engineered prompts, recent works learn prompts using training data from downstream tasks, but this can be expensive and hard to generalize to new tasks and distributions. To this end, we propose test-time prompt tuning (TPT) as the first prompt tuning method that can learn adaptive prompts on the fly with a single test sample. TPT optimizes the prompt by minimizing the entropy with confidence selection so that the model has consistent predictions across different augmented views of each test sample

What does "stationary" mean in the context of reinforcement learning?
I think I've seen the expressions "stationary data", "stationary dynamics" and "stationary policy", among others, in the context of reinforcement learning. What does it mean? I think stationary pol...
A stationary policy is a policy that does not change. Although strictly that is a time-dependent issue, that is not what the distinction refers to in reinforcement learning. It generally means that the policy is not being updated by a learning algorithm
Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing...
Adaptive gradient algorithms borrow the moving average idea of heavy ball
acceleration to estimate accurate first- and second-order moments of gradient
for accelerating convergence. However,...
Adaptive gradient algorithms borrow the moving average idea of heavy ball acceleration to estimate accurate first- and second-order moments of gradient for accelerating convergence. However, Nesterov acceleration which converges faster than heavy ball acceleration in theory and also in many empirical cases is much less investigated under the adaptive gradient setting. In this work, we propose the ADAptive Nesterov momentum algorithm, Adan for short, to effectively speedup the training of deep neural networks. Adan first reformulates the vanilla Nesterov acceleration to develop a new Nesterov momentum estimation (NME) method, which avoids the extra computation and memory overhead of computing gradient at the extrapolation point. Then Adan adopts NME to estimate the first- and second-order moments of the gradient in adaptive gradient algorithms for convergence acceleration