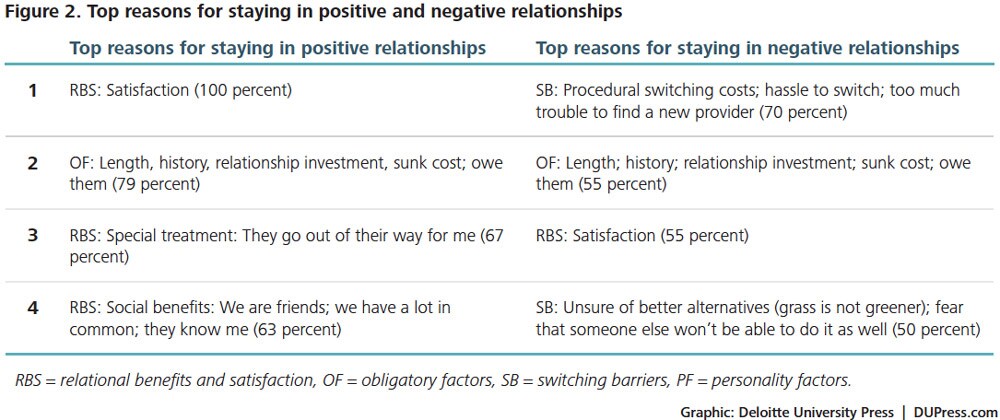
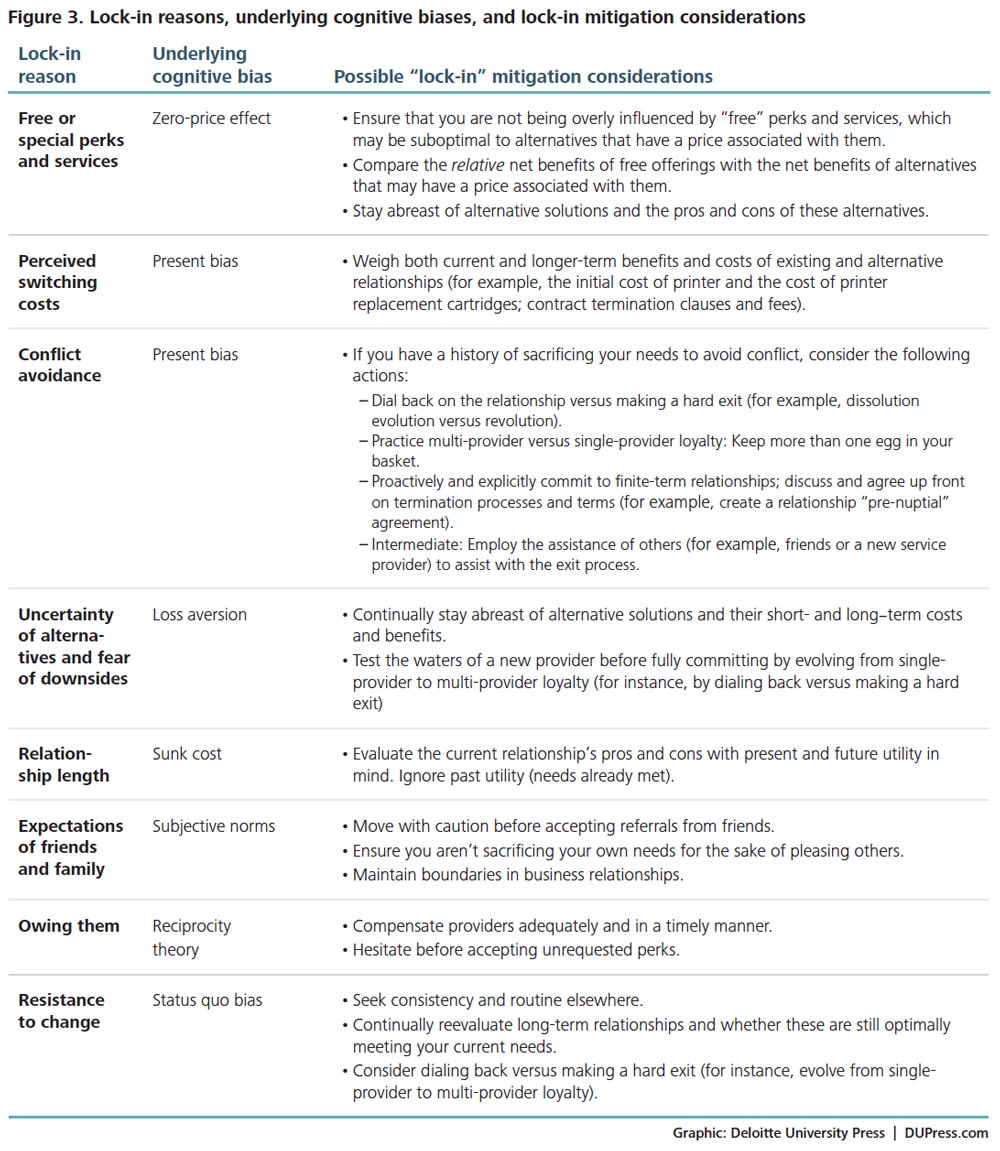
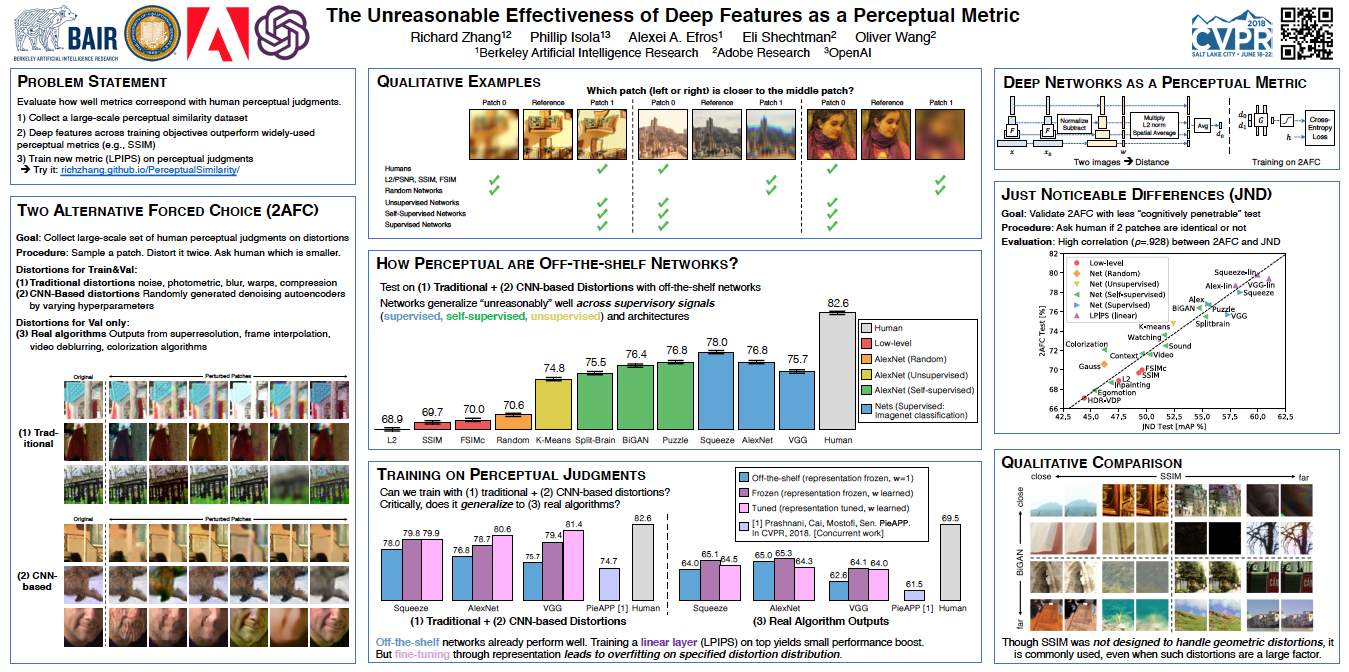
We have the privilege of meeting with thousands of entrepreneurs every year, and in the course of those discussions are presented with all kinds of numbers, measures, and metrics that illustrate the promise and health of a particular company. Sometimes, however, the metrics may not be the best gauge of what’s actually happening in the business, or people may use different definitions of the same metric in a way that makes it hard to understand the health of the business.
So, while some of this may be obvious to many of you who live and breathe these metrics all day long, we compiled a list of the most common or confusing metrics. Where appropriate, we tried to add some notes on why investors focus on those metrics. Ultimately, though, good metrics aren’t about raising money from VCs -- they’re about running the business in a way where you know how and why certain things are working (or not), and can address or adjust accordingly. MORE
A common mistake is to use bookings and revenue interchangeably, but they aren’t the same thing.
Bookings is the value of a contract between the company and the customer. It reflects a contractual obligation on the part of the customer to pay the company.
Revenue is recognized when the service is actually provided or ratably over the life of the subscription agreement. How and when revenue is recognized is governed by GAAP.
Investors more highly value companies where the majority of total revenue comes from product revenue (vs. from services). Why? Services revenue is non-recurring, has much lower margins, and is less scalable. Product revenue is the what you generate from the sale of the software or product itself.
ARR (annual recurring revenue) is a measure of revenue components that are recurring in nature. It should exclude one-time (non-recurring) fees and professional service fees.
ARR per customer: Is this flat or growing? If you are upselling or cross-selling your customers, then it should be growing, which is a positive indicator for a healthy business.
MRR (monthly recurring revenue): Often, people will multiply one month’s all-in bookings by 12 to get to ARR. Common mistakes with this method include: (1) counting non-recurring fees such as hardware, setup, installation, professional services/ consulting agreements; (2) counting bookings (see #1).
While top-line bookings growth is super important, investors want to understand how profitable that revenue stream is. Gross profit provides that measure.
What’s included in gross profit may vary by company, but in general all costs associated with the manufacturing, delivery, and support of a product/service should be included.
TCV (total contract value) is the total value of the contract, and can be shorter or longer in duration. Make sure TCV also includes the value from one-time charges, professional service fees, and recurring charges.
ACV (annual contract value), on the other hand, measures the value of the contract over a 12-month period. Questions to ask about ACV:
What is the size? Are you getting a few hundred dollars per month from your customers, or are you able to close large deals? Of course, this depends on the market you are targeting (SMB vs. mid-market vs. enterprise).
Is it growing (and especially not shrinking)? If it’s growing, it means customers are paying you more on average for your product over time. That implies either your product is fundamentally doing more (adding features and capabilities) to warrant that increase, or is delivering so much value customers (improved functionality over alternatives) that they are willing to pay more for it.
Lifetime value is the present value of the future net profit from the customer over the duration of the relationship. It helps determine the long-term value of the customer and how much net value you generate per customer after accounting for customer acquisition costs (CAC).
A common mistake is to estimate the LTV as a present value of revenue or even gross margin of the customer instead of calculating it as net profit of the customer over the life of the relationship.
GMV (gross merchandise volume) is the total sales dollar volume of merchandise transacting through the marketplace in a specific period. It’s the real top line, what the consumer side of the marketplace is spending. It is a useful measure of the size of the marketplace and can be useful as a “current run rate” measure based on annualizing the most recent month or quarter.
Revenue is the portion of GMV that the marketplace “takes”. Revenue consists of the various fees that the marketplace gets for providing its services; most typically these are transaction fees based on GMV successfully transacted on the marketplace, but can also include ad revenue, sponsorships, etc. These fees are usually a fraction of GMV.
A good proxy to measure the growth — and ultimately the health — of a SaaS company is to look at billings, which is calculated by taking the revenue in one quarter and adding the change in deferred revenue from the prior quarter to the current quarter. If a SaaS company is growing its bookings (whether through new business or upsells/renewals to existing customers), billings will increase.
Customer acquisition cost or CAC should be the full cost of acquiring users, stated on a per user basis. Unfortunately, CAC metrics come in all shapes and sizes.
One common problem with CAC metrics is failing to include all the costs incurred in user acquisition such as referral fees, credits, or discounts. Another common problem is to calculate CAC as a “blended” cost (including users acquired organically) rather than isolating users acquired through “paid” marketing. While blended CAC [total acquisition cost / total new customers acquired across all channels] isn’t wrong, it doesn’t inform how well your paid campaigns are working and whether they’re profitable.
Burn rate is the rate at which cash is decreasing. Especially in early stage startups, it’s important to know and monitor burn rate as companies fail when they are running out of cash and don’t have enough time left to raise funds or reduce expenses























{kind=link}
{kind=link}
{kind=link}
{kind=link}